notes: Aurora
Aurora
让我们继续 6.824 阅读。Lecture 10 的标题是:
Lecture 10: Database logging, quorums, Amazon Aurora
与前面的 Raft/CRAQ 不同,Aurora 展示了一种技术很牛逼也卖得很好的共享存储架构。我们可以说这是经过了考验的设计良好的架构。
6.824 主要介绍的是 AZ 和 Quorum,虽然这些东西都很厉害,不过我总觉得没介绍 Aurora 最牛的东西?
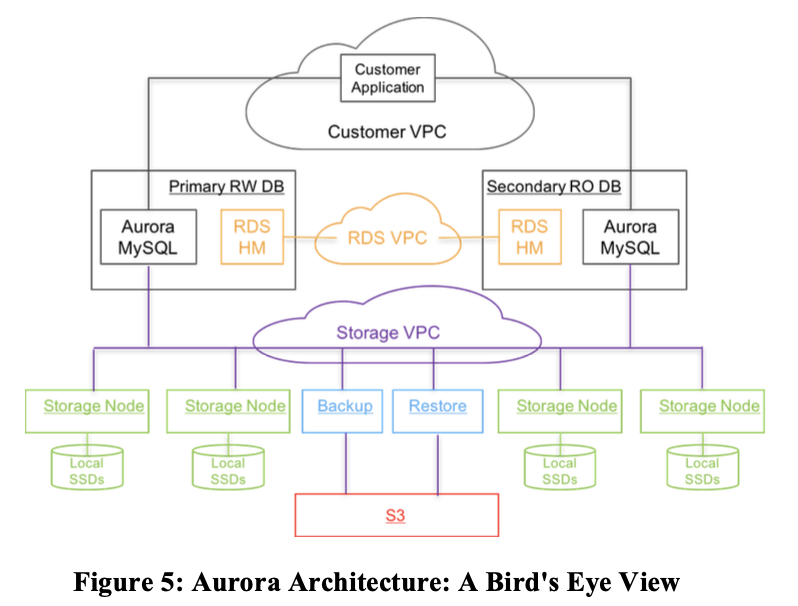
EC2 是 Amazon 的云服务器,由本地的 SSD,并有多租户等特性,S3 是亚马逊的对象存储. 在 S3 上存上去了能保证安全性。
这里的 RW 表示有读/写权限的 Primary, RO 表示只读的机器。运算节点机器部署在 Amazon 的 VPC 上,而存储依赖于部署在各地、有本地 SSD 的存储节点。它也会产生类似 binlog 的文件,同步到 Amazon S3 对象存储上。
6.824 给了一些 AWS 服务的介绍:
1 | EC2 is great for www servers |
此外还需要介绍 Amazon EBS, 即 Block Store,AWS 的块存储。
1 | Amazon EBS (Elastic Block Store) |
传统的 Mirror 方案 Pipeline 如下:
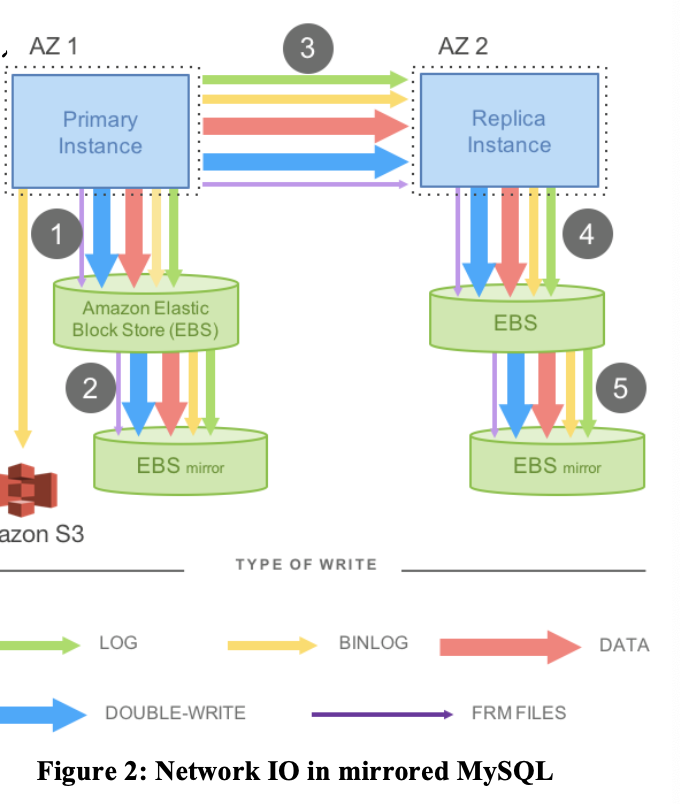
(异步的方案或许只要读取 binlog, 但是同步复制则需要做上面的操作 https://dev.mysql.com/doc/refman/8.0/en/replication-semisync.html)
上述的操作或者方案会带来很大的写放大。此外,Aurora 认为,在一个集群中,慢的机器和慢的/同步的操作很容易成为瓶颈,例如:
- 事务的 Commit 阻塞冲突的事务
- 分布式事务的 2PC
- 单机的 Cache Miss
Aurora 把上层保留(不过可能也要做一些适配),然后在存储层替换为了分布式的:
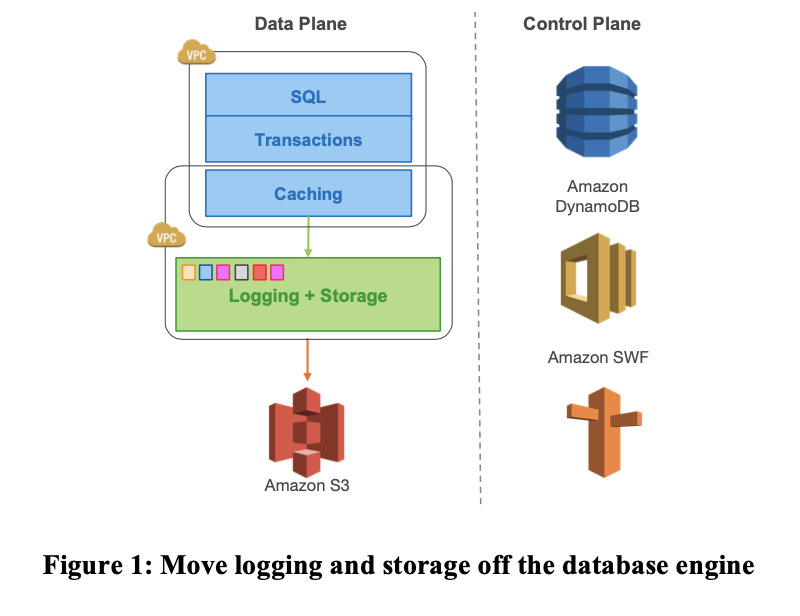
First, by building storage as an independent fault- tolerant and self-healing service across multiple data-centers, we protect the database from performance variance and transient or permanent failures at either the networking or storage tiers. We observe that a failure in durability can be modeled as a long- lasting availability event, and an availability event can be modeled as a long-lasting performance variation – a well-designed system can treat each of these uniformly [42]. Second, by only writing redo log records to storage, we are able to reduce network IOPS by an order of magnitude. Once we removed this bottleneck, we were able to aggressively optimize numerous other points of contention, obtaining significant throughput improvements over the base MySQL code base from which we started. Third, we move some of the most complex and critical functions (backup and redo recovery) from one-time expensive operations in the database engine to continuous asynchronous operations amortized across a large distributed fleet.
Aurora 主要思路是:
- 提供共享的存储和 RWN, 在多个可用区保证可靠性
- The log is the database, 共享存储与 Log
- 基于(2) 的事务
我觉得 1 其实很好理解,2对我这种没看过的比较新奇,但是也可以理解,3这段很难
存储
1 | Goal: better fault tolerance by cross-AZ replication |
Available Zone 可用区,简单理解类似于阿里云 xx 机房,特性是:
- 内部机器物理上大概很接近,零点几毫秒 ping 一下
- 硬件一般故障其实概率都差不多,但是高温、发洪水、网络延迟之类的可能导致整个机房都不可用
Aurora 采取3AZ + 每个 AZ 两台的形式,在 RWN 协议下保证了:
- 一个 AZ 内全部坏掉 + 额外坏一台,是可读的
- 一个 AZ 全部坏掉,是可写的
(我的问题是这样写入不会延迟巨高么=。=)
Aurora 将:
- 长期的机器坏掉
- 短暂的网络延迟
- 更新
上述的问题都视作系统的不可用。现在它想要保证的是:
- 无法减少故障修复时间
- —> 希望减少 MTTF (平均故障间隔),来让上述不可用很少发生,保证系统有 Quorum
Aurora 采用 Segment Storage, 来分10G段存储,分段修复。
之所以选择10G,是因为在万兆网络条件下,恢复一个数据段只需要10秒钟。在这种情况,如果要打破多数派,那么必须同时出现两个数据段同时故障加上一个AZ故障,同时AZ故障不包含之前两个数据段故障的独立事件。通过我们对故障率的观察,这种情况出现的概率足够低,即使是在我们现在为客户服务的数据库量级上。
以上的是模型上的思路,Aurora 提供了 EBS 级别的容错:
- EBS 部署在上述所叙述的情况下,来保证写入的 Quorum
话说 6.824 在这里简单介绍了一下 Quorum read/write,Amazon 在实现 Dynamo 的时候也用了这套:
- 可能写入需要维护版本
- N 是总副本的数量,R是读的数量,W是成功写的数量,那么:
- R + W > N, 即刻说明读写必定有交集,必定能读到写入的数据
6.824 介绍如下:
1 | the goal: fault-tolerant storage, |
下面是它的 pros and cons
1 | What is the benefit of quorum read/write storage systems? |
同时,数据按照 segment 进行 sharding:
1 | What if the database is too big for a replica to fit into one storage server? |
The log is the database
Aurora 只会同步 Redo Log,而不要像之前的 MySQL 那样同步很多别的 write 操作。Redo log 描述要进行的操作。日志和存储层下沉到了存储节点。你可能会记得下面的:

这要求系统大概要满足 no-steal/no-force 的特性:未完成事务的页不能刷到盘上. 我们会在 Log 部分再次讨论这一段。
1 | Storage servers understand how to apply DB's log to data pages |
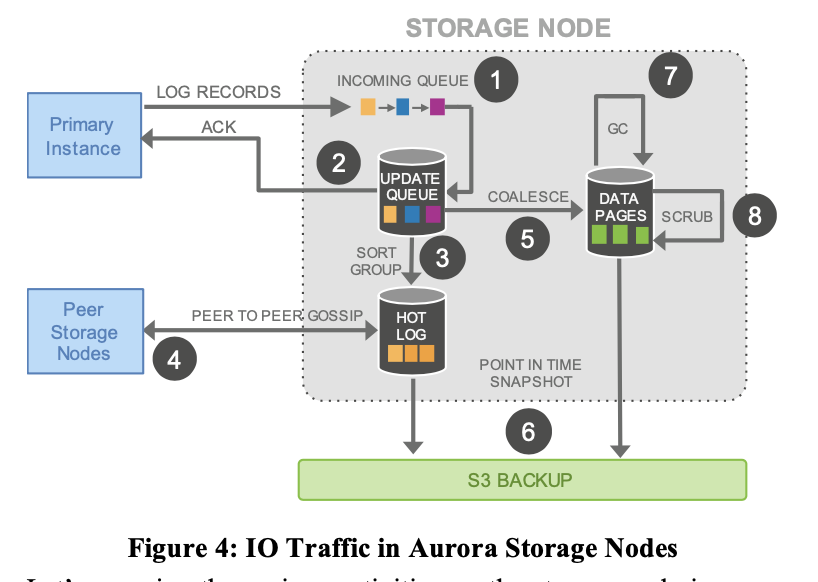
通过上述的策略和异步的 apply, Aurora 减少了写入的延时:log 写入放入 Update Queue 即可,大大降低了 Latency.
日志和 SQL
Log 需要对应的 LSN。对日志处理的层在 Storage Layer 上,所以它们知道日志的语义,能够 apply 这些日志。
以上的写入流程是过于简单的,然而读总要读到像样的东西吧!既然和 MySQL 来 PK,总要有事务的语义吧!
数据库要确认下列信息:
- VCL(Volume Complete LSN):保证之前都被持久化的 LSN
- CPL(Consistency Point LSN):对于事务的语义的 CP
- VDL(Volume Durable LSN): 副本最大的 CPL
CPL必须小于或者等VCL,所有大于VDL的日志记录都可以被截断丢掉
那么,甚至 VDL 之前的一些都要在语义上视作没 Commit. 写入北推进的时候,VCL CPL VDL 被推进,来实现事务的语义。
6.824 对 Log Write 有个比较精炼的描述:
1 | What does an Aurora quorum write look like? |
在写入的时候,你要写 Quorum, 然后 VDL > 日志的 CPL 时, 提交就是安全的,你可以 Commit 了。
读取的时候流程如下:
1 | What does an ordinary Aurora read look like? |
数据库建立一个读时间点,表示这个时候读到什么数据是安全的,然后在对应 Segment 下读.