SSD as Cache and CacheLib
SSD 特性回顾
SSD 的重要组成部分是 NAND Flash,在介绍 SSD 的时候,我们需要理解 NAND Flash 的一些基本性质。
Flash 包含很多 Block,而 Block 通常由很多 Page 组成。读取 (read) 的单位通常是 Page,Program 也是针对单个 Page 进行写入的。而重要的擦写(Erase)意味着,我们需要重写某个 Page 的话,我们可能需要给整个 Block 内容移除:
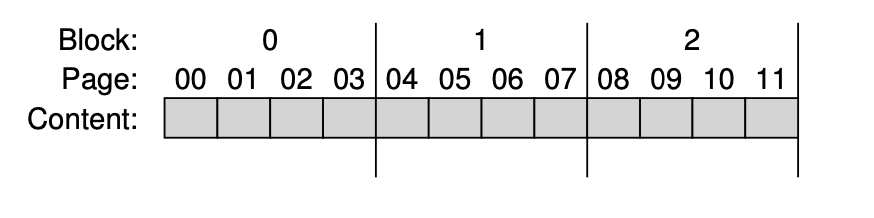
通常,Flash 的擦写次数是有上限的,而 SSD 会包含 FTL 层,来协调对 SSD 的写入。
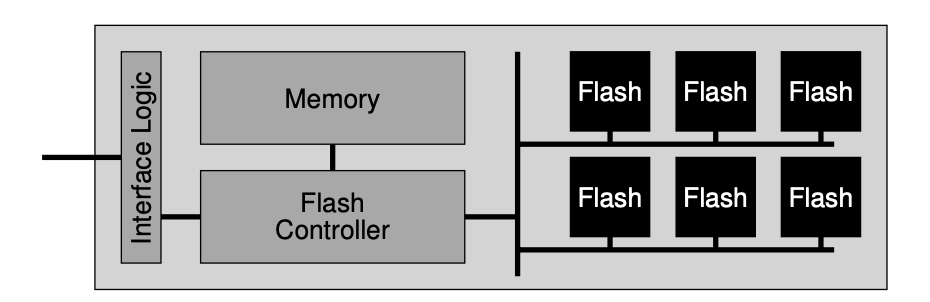
对 SSD 的写入可能还会需要 GC,因为 Erase/Program 是不同粒度的,所以 SSD 可能是需要 GC 的。假设:
- 前台没有空间供 SSD 写入
- 后台希望整理碎片,在有的 Block 中,可用的逻辑块很少了
那么我们希望有一个 GC 来清理这些资源
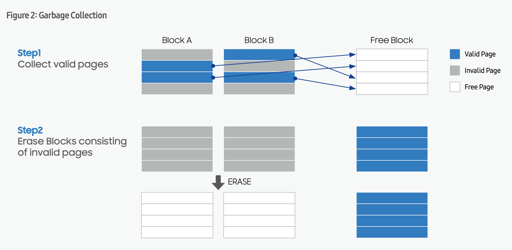
上述图片演示了 GC 的过程。这中间需要有一部分额外空间来做 GC,比方说 SSD 提供 1TB 的空间,那么它需要有一定的内存来处理 NAND Flash 物理空间和逻辑空间的映射,同时,需要有一定空间来协助 GC,这部分空间叫做 over-provisioning (OP).
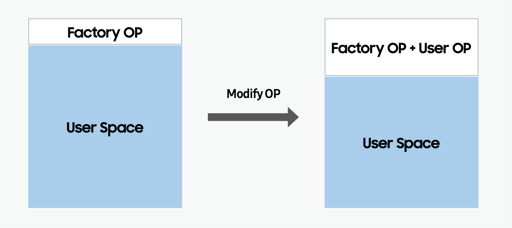
SSD 也可以在用户层配置更多的空间给 OP,这种配置能够让 SSD 有更多的空间做 GC,对于 random write 比较多的 SSD,实际上可以提供一定的性能优化,如下图:
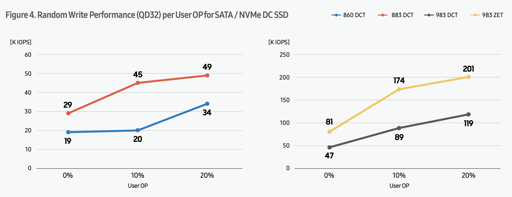
以上是阅读后文之前需要理解的 SSD 知识。
为什么为 SSD 设计缓存需要额外的数据结构
实际上,现有已经有比较多的 kv-store 了,包括著名的 RocksDB。主要的问题在于,Cache 中,如果不再引用某份数据,那么删除掉它是安全的。而 KV 存储引擎即使不保留多个版本,也一定会保留它。drop 一份数据的时候,甚至会 log 一个 tombstone,再慢慢清除存储的数据。
Netflix 使用 RocksDB 做小文件缓存,这使得它有大量的空间浪费,并且要开启较高的 OP。
CacheLib
CacheLib 本身是 Facebook 以库的形式提供的缓存库。开发这个库主要是因为 Facebook 内部有很多需要用缓存的地方,包括 CDN、应用的 Look-Aside Cache、对 Storage System (比如图片和小对象)的 Cache。如下图:
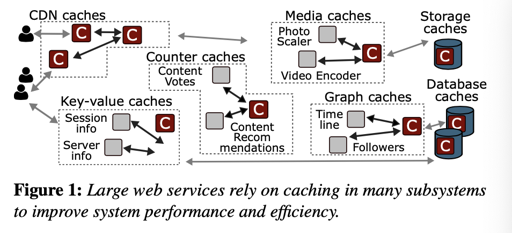
过去这些团队都需要独立维护 Cache,也开源了像 memcached 一样的产品。但实际上这些团队相当于要造一套适用于自己的缓存。不同团队的缓存是不太一样的,论文里面展现了不同地方的使用场景:
- CDN,使用 DRAM 和 Flash 做 Cache
- 应用的 Look-Aside Cache,可能会运行一个比较大的 Memcache 集群,并且通过 RPC 来访问这些数据。
- 应用的 In-Process Cacahe. 这个和上面的 Look-Aside Cache 是一个相对的概念,因为对一些 app 来说,它自己需要缓存部分数据,比如 client session。
- 机器学习模型缓存
- 存储集群缓存。Facebook 使用大量的 HDD 作为缓存,部分时候可能希望前台能够缓存在机器的 SSD 中。
- 数据库的页缓存。这个需要和 DB 的逻辑强相关。
在数据特征上,这些也呈现出很多不同:
- 数据的冷/热是不同的,小部分数据可能承担了大部分流量。
- 数据的冷/热变更的很快
- 暴读的情况很多
- 需要缓存的对象涵盖了不同的大小范围
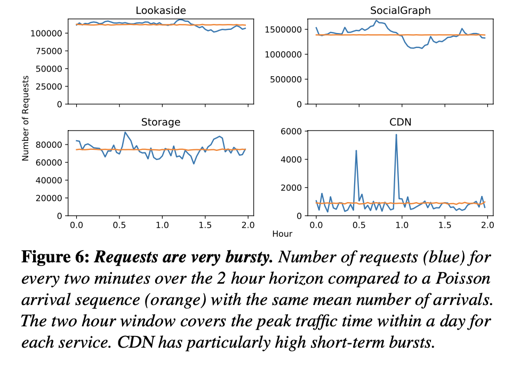
关于冷热数据想必不用赘述。冷热变化可以见下图:
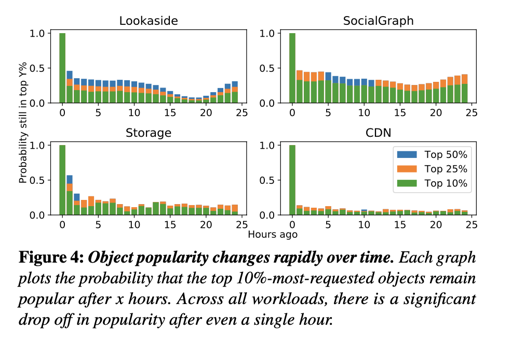
可以看到系统的冷热变化趋势。对象大小和暴读情况也如图:
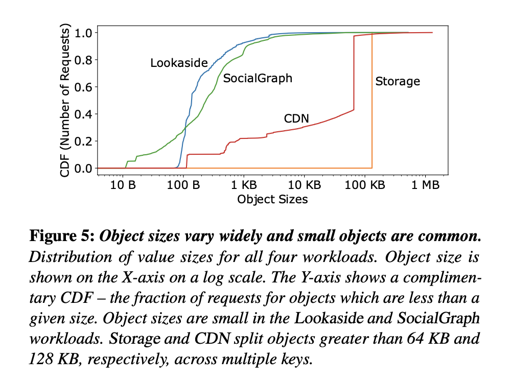
相对来说这些东西需要写很多相同的缓存逻辑:换出策略,内存使用,处理 empty cache 等,所以 Facebook 造了一套通用的 CacheLib,用来节省团队造轮子的功夫。
同时,很重要的一点是对于 Flash 的使用。用 SSD/Flash 当缓存,相对来说能够提供较低的成本,和可以接受的性能。相对 DRAM,机器一般会提供更大的盘,同时,SSD 也会提供更低的成本和更可接受的性能。这套功能在 CacheLib 中叫做 HybridCache,CacheLib 允许指定存储设备。
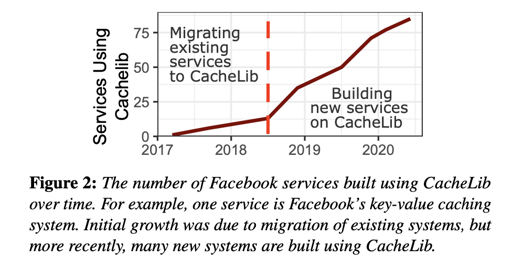
目前 Facebook 的 CacheLib 使用率:
Cache Interface
CacheLib 对外提供的是 byte-addressable 的对象和 cache。它提供了一套线程安全的 api,来处理对应的逻辑:

此外,CacheLib 还给自定义的 Serialize/Deserialize 定义了接口,以便用户塞一些自定义结构体。
Cache Storage
CacheLib 将缓存分为了几部分:
- DRAM Cache
- LOC (Large Object Cache)
- SOC (Small Object Cache)
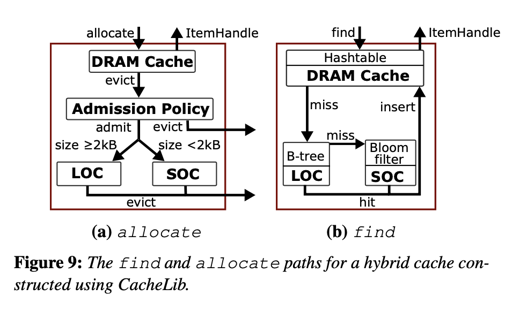
申请的内存会出现在 DRAM cache 中,论文使用 chained hash 来存放 DRAM Cache,同时可以自己配置换出的策略。需要注意的是,这里给内存中的缓存可以配置 Pool,每个 Pool 可以自己设置换出策略等。感觉这相当于交给用户自己管理内存使用方式了。
这里使用了 slab classes 管理内存,这里 CacheLib 自己实现了一套节省空间的 slab allocator,然后对里面的并发进行了优化。
当对象从 DRAM 缓存中 evict 的时候,会按照一定的策略决定是换到 Flash 中还是 Expire。作为默认策略,CacheLib 会固定按照概率 $p$ 来决定是否从 DRAM 中接收数据。
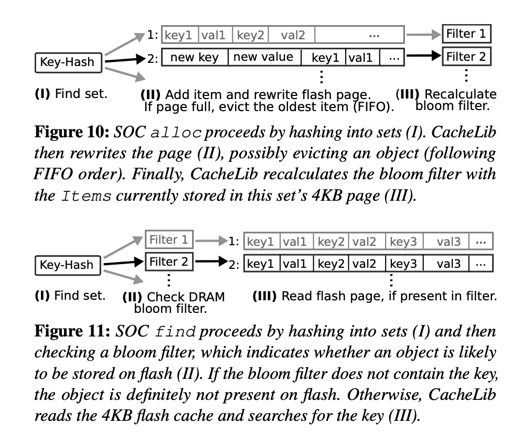
Flash 上的存储区分了大小对象的存储,大对象是指不小于 2kB 的对象,小对象则自然指的是小于 2kB 的对象。因为 SSD 的特性,这两种对象需要有不同的处理方式。
LOC: 内存索引 + SSD
LOC 存储的都是 2kB 以上的对象. 作者认为,这些大对象让用户能够在内存中放置这些对象的 Index。具体的对象按照 4kb 的大小对齐。论文用了 4Bytes 的大小定位这部分的数据:4bytes 最大能表示 $2^{32}$ 个数据,可以放 16T 的数据了。
LOC 的内存索引存储 <Key, Location>,LOC 会主动把 SSD 划分成不同的区域,根据这个来判断大小。然后 LOC 对象的地址会对齐 4kB,这大概是一个 SSD Page 的大小,这样能够保证:
- 一个 SSD Page 不会存储过多的对象
- 地址对齐 4kB,减小地址对象的开销。
同时,如果对象很大,那么它会连续跨多个页。需要把他们都读起来。
如果一个 cache read 读取有一个相同的 hash key,这里会把 Flash 中的元数据读起来。这里在元数据上需要存储对应的 key。然后把这个 key 跟用户请求的真实 key 比较,判断具体是否命中缓存。
这里还有一个 Erase 相关的优化。LOC 的 Erase 是以 Block 为单位的,它默认 16MB,但是是可配置的。这实际上相当于 抹去 SSD 的 Block,通过这种方式来增加写的顺序写。如果淘汰出的对象是一个比较热的对象,可能会重新加入 cache 中。
SOC: Page 存储
SOC 存储很多小对象,如果像 LOC 一样存储它们的索引,系统整个 DRAM 开销会非常大。所以 SOC 使用了一个近似的索引来实现对应的逻辑。
SOC 把小对象划分成很多 sets,每个包含一个 4kB page,按照 FIFO 存储对象。每组有一个 8Bytes 的 bloom filter。这里把 key 查一下 Bloom Filter,如果不存在则返回不存在,否则读取整个 Page 并顺序扫描。
总结
CacheLib 论文感觉主要还是说这玩意的必要性,关于细节讲的比较少,内存部分描写比较细(但是这应该是一个很老的主题),Flash 部分 LOC 感觉写的细一点,SOC 根本不能细想。不过这篇文章确实介绍了,相对于 RocksDB,为什么需要 SSD 缓存。
论文绝大部分篇幅讲的是必要性和工程优化,可以看到 Facebook 确实抠的很细,但是我看了眼代码,感觉 Slab 这些优化都实现了,Flash 部分没看到这些东西存在…
Kangaroo: Caching Billions of Tiny Objects on Flash
这篇是 CMU + Facebook + MSR/UW 一起写的,不知道是不是因为 Cache SSD 像一个香饽饽。但是这篇文章感觉比 CacheLib 这篇详实了很多,确实像个正经研究了。
Kangaroo 的落脚点在小对象优化上,论文考察了 SSD 的下面几个维度:
- 写放大
- 来自 SSD 的写放大
- 来自应用的写放大
- 内存开销
- SSD 空间开销
然后采用了权衡的策略,并结合 SSD 的特点来选出了一个很优的结构。
论文认为,把 SSD 作为缓存有下列几种 Pattern:
- Log Structure + Index
- Set-associative
Log + Index 通常是,收到一个小对象的时候缓存下来,直到达到一个 Page(或者数个 Page) 的大小,然后顺序的 Log 这个 Page。考察这种方式的时候,我们会发现,它有着不错的前台写性能,但是 (1) 会需要比较大的内存索引 (2) 有可能需要 GC 等方式回收空间。论文作者着重强调了索引方面的问题。
Set-associative 以类似 CPU-Cache 的组相联的方式组织,这种方式将 SSD 分为几个部分,然后 hash(key) 找到对应的部分,查看 key 是否存在于其中。这种方式会有非常严重的写放大,因为可以看到,很多情况下,对它的写入都会变成随机写。
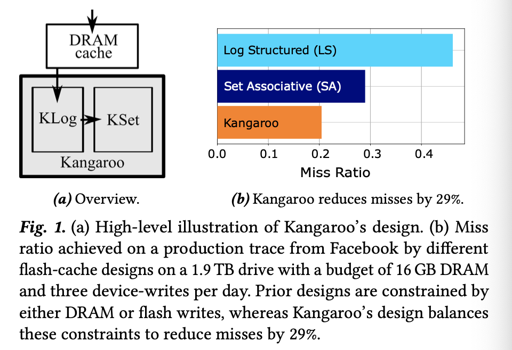
Kangaroo 选用了大部分 cache 空间用作 set-associative cache ,并称其为 KSet,然后拿一个小部分的缓存作为 Log + Index 的缓存 KLog,作为 KSet 的写入前台。KLog 每次把同一组的数据一起丢到 KSet 里,用 batch 的方式优化了 KSet 的写放大。
Kangaroo 的设计有几个 Key-Point:
- 使用 partitioned index,来使 KLog->KSet 的数据处于同一个 KSet 的 Set
- Kangaroo 可以 drop 掉 value,它不是 kv,只是一个缓存,KLog 里面的内容甚至可以不写入 KSet,这可以由某个策略来决定。Kangaroo 实现了 threshold admission,来决定是否要接纳 KLog 淘汰下来的值。
- Kangaroo 提出了新的针对 KSet 的换出策略来进行优化
SSD 的写放大
论文里将 SSD 的写放大分为了下面两种:
- Device-level write amplification (DLWA):SSD Erase/GC 等带来的写放大。随机写会使 DLWA 恶化,从而需要配置更多的 OP。
- Application-level write amplification (ALWA):当应用重写自己的 Page 等内容的时候,例如 LSM-Tree Compaction。
实际上,CacheLib 的策略在 DLWA 和 ALWA 上都是很差劲的,因为它会造成非常多的随机写,和反复重写 Page。Kangaroo 可以靠 Grouping/Batching 来优化它。
Log-structuredcaches & Set-associative flash caches
Kangaroo 流程
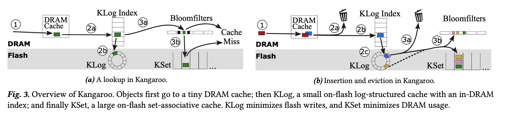
写入
这里的内容首先会落到 DRAM cache 中,随着 DRAM cache evict,它会按照一定概率进入 KLog。写入 KLog 的时候,这里会往 KLog 中插入对应的对象,然后在 KLog Index 中插入对应的条目。KLog 大概占整个 Flash 存储空间的 5%。随着写入,记录可能会被 batch 淘汰到 KSet 中,然后写入对应的 Bloom Filter。
读取
- 先从 DRAM Cache 中查询内容,如果存在则返回
- 从 KLog Index 中查询内容,如果查询到则进入 KLog 查找
- 如果不存在,则进入 KSet,从 Bloom Filter 找到对应的内容,如果存在则进入 KSet 寻找
KLog
KLog 有一个概率 $p$,前来的对象只有这个概率能进入 kangaroo。相比之前 CacheLib 的设计,由于 Batching 写入的优化,Kangaroo 大部分时候不会 discard 掉对象。
KLog 的目标是,降低整体的 ALWA,同时不增大内存的开销。它需要支持下面的操作:
LOOKUPINSERTEnumerate-Set: 使 KLog 寻找出所有映射到同一个 KSet 的对象。
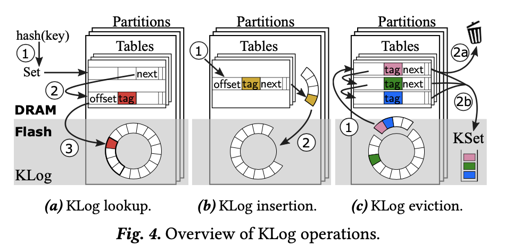
为了高效支持 Enumerate-Set,KLog 的内存 Index 被设计为 Bucket + Chain hashing。这里会让在同一个 KSet 的集合的对象落到同一个内存中的 Bucket。
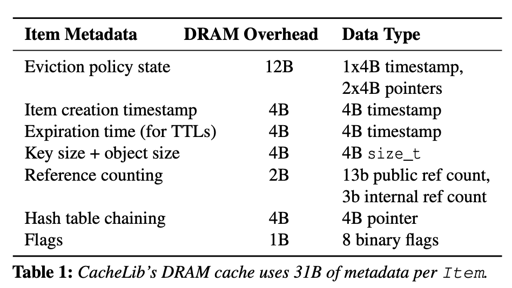
这里 KLog Index 的结构可见于下面的 Table1,每个 Item 需要:
- offset, 标示在 KLog 的 Log 环上存储的位置
- Tag,key hash 有关的值,实际上帮助我们推断最终这个条目会映射到哪一个 KSet 的 Page 上
- Next-pointer: 指向 bucket 内的下一个 Item
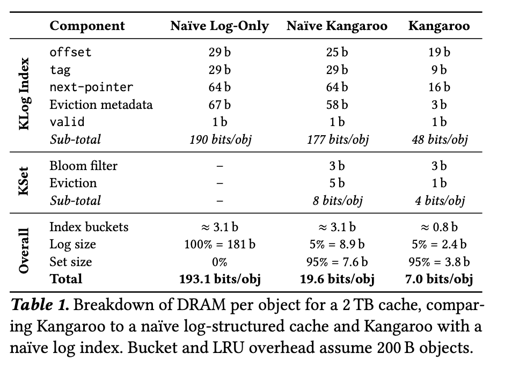
可以看到,在 size 上,论文对这几个必须的结构的大小做出了优化,使得它们占用了更小的内存空间。不过大概的思路还是一致的:
- Lookup: 找到对应的 bucket,然后忽略掉 invalid item,根据
tag找到对应的 key。如果没找到,返回 Miss,否则根据 offset,在 Log 上寻找,然后验证整个 key 下盘上的 log 是一致的。KLog 在 Index 上更新 evict 相关的元数据。 - Insert: 插入 Index,然后把对象插入 DRAM Buffer。Buffer 以单个/多个 Page 的一个 Segment 为粒度,保证它是连续的。等到写满 Buffer 的时候,Log 到存储上。
- Enumerate-Set: 在同一个 bucket 里面,找到在同一个 Set 中的对象。
此外,如图所示,这里按照 KSet 的布局,分成了不同的 partition index,每个 partition index 有独立的 DRAM 和 Flash 空间。这种结构希望能够将 KLog 和 KSet 结构整合更加紧密,同时,在结构设计上,作者可以用一定的 Hack 减少内存开销(见论文 4.2)。论文把单个 Item 压缩到了 48bits,给 Index 省了很大的 DRAM 空间。
KLog → KSet
KLog 的写放大不是什么问题,我们回顾一下,它的前台几乎没有什么写放大,写的话小对象会填充完 Page 再写。ALWA 和 DLWA 都会很小。为了减小 KSet 的写放大,这里需要 batching 导入 KSet。同时,这里需要了解,KSet 是可以 Reject 写入的。
Kangaroo 有一个后台线程会保证每个 partition index 有一个空余的空间,供 Buffer Log 写入。KLog 会以 Segment 的形式来 evict,这里流程如下:
- 对 Segment 中的每个对象,会调用
Enumerate-Set来枚举出同一个 Set 的所有对象,并尝试写入 KSet。 - 如果
Enumerate-Set对象没有到达 batching 写入阈值,那么 discard 掉这个 Segment 上的这些对象。如果某个 discard 的对象是比较热的对象,那么会重新插入 KLog 。
系统在 (2) 上有一个阈值。这个阈值会影响 KSet 的 ALWA。系统认为,这个值应该保证,在大小上,KLog 是 KSet 的 5% 左右即可。阈值增大会降低 ALWA,但是会增加 cache-miss。
KSet
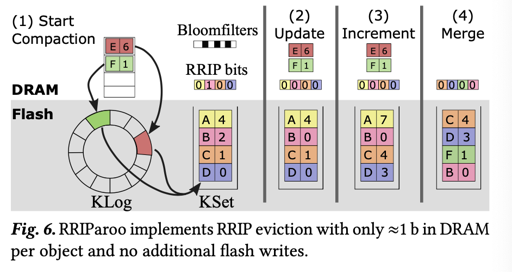
KSet 的逻辑和 CacheLib 的逻辑是相同的,不同的是,这里额外在内存中维护了一个 RRIP bits。这个 RRIP bits 相当于用很少的 bits 维护了插入的优先级。
这里的逻辑比较像 MySQL 的缓存 replacement rule,它会在中间一个位置插入。相对于原本 CacheLib 的 LOC,这里相当于用 batching 写入 + Cache Replacement,优化了写放大和缓存命中率。
这一段优化主要在 RRIP 算法上,详细可以看论文的 4.4。
总结
Kangaroo 这篇论文看上去科学了很多,用 Log-Struct 和 Set-associate 两种结构讲了一个比较合理的故事,并且既有一些量化的计算,也有一些实际的工程优化。相对来说,CacheLib 的论文还是大部分在吹自己的场景,只有一节含糊讲了下具体实现,这篇还是做了很扎实的讨论的。
CacheLib 主分支并没有合并 kangaroo 有关的代码,具体的线上可靠性还有待验证。