InfluxDB 模型和存储引擎入门
InfluxDB 分为这里所列的版本:https://www.influxdata.com/products/editions/
数据模型和查询
参考:https://docs.influxdata.com/influxdb/v2.1/reference/key-concepts/data-elements/ 和 https://docs.influxdata.com/enterprise_influxdb/v1.9/concepts/glossary/
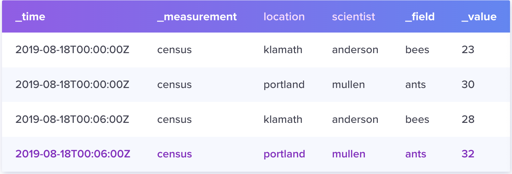
- Database: 数据库
- Timestamp: 时间戳,
- Measurement: A measurement acts as a container for tags, fields, and timestamps.
- Field: 分为
<Field Key, Field Value>,Field Key 是名称字符串,Field Value 是只支持基本类型的值。所有的 Field 组成了一个 Field Set,Field 上的值是不会建索引的。 - Tags 是提供
Point的元数据,有点类似 index,tags 按照string的方式存储. 所有的 tags 组成了 tag set。单个 Tag 包含Tag Key和Tag Value. 对于每个 tag key, tag value 可以构成一个类似 Card 的概念- 可以理解成,tag 本身都是 string 类型
- tag 可以构建索引
那么,如上所述,InfluxDB 的 Schema 如下表示:
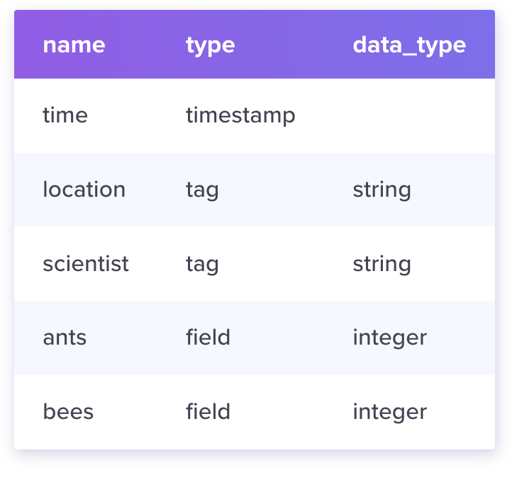
理解了上面的东西之后,需要理解 Series 和 Series Key 这两个概念:

和 Series: 包含 timestamp 和

看到没有,这里相当于统计信息给抽出来了,一个 Series Key 对应一个 Series,而这个 Series 有着多个 <Timestamp, Field Value> 组下面才定义到具体的信息:
Point: 对应的单个 Series Key + <Timestamp + Field Value>, 可以理解成数据库的「行」。
最后,measurement 类似 RDBMS 的 表,而这里给出一个 Bucket 的概念,可以设置多个 measurement,并且设置一些 expire time 之类的条件。
以上就是 InfluxDB 的基本概念,具体一些 Schema 定义可以看:https://docs.influxdata.com/influxdb/v2.1/reference/key-concepts/data-schema/
Line Protocol
InfluxDB 可以使用 Line Protocol: https://github.com/influxdata/influxdb/tree/master/tsdb#line-protocol
query & latency
Timescale 给出了一个 benchmark,我觉得这种 benchmark 肯定都是自己吊打别人,但是对衡量数量级来说帮助很大,如下图:
https://www.timescale.com/blog/content/images/2022/01/20200716_Timescale_Blog_InfluxBenchmarks.jpg
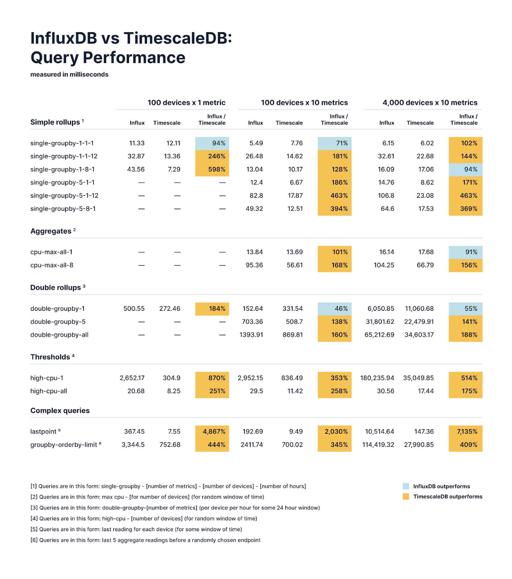
可以看到,对这个的查询包含一些近实时的查询,而数据可能能在 ~100ms 左右的时间完成一些简单的 GroupBy。
Shard
Sharding is the horizontal partitioning of data in a database. Each partition is called shard. InfluxDB stores data in shard groups, which are organized by retention policy and store data with timestamps that fall within a specific time interval.
因为时序数据库是一个偏分析的场景,所以按照时间分片是一个相对自然的策略。这个分片有一个 RP(Retention Policy),是说保留具体内容的时间。我们都知道,Bucket 本身有一个过期时间配置,Shard Group 会按照 Bucket 的时间再切细一点,做过期时间配置:
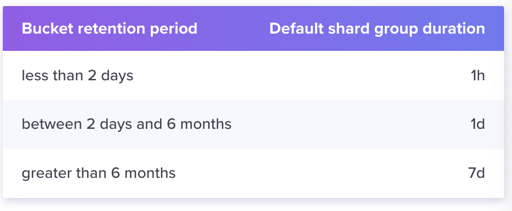
再开源 InfluxDB 上,一个 Shard Group 只有一个 Shard,感觉很无力:
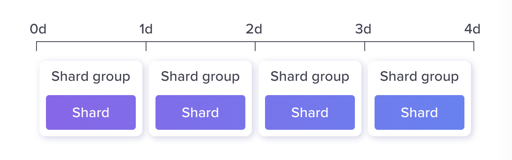
InfluxDB Enterprise 则不一样,它可以配置 Shard 的复制等功能:https://docs.influxdata.com/enterprise_influxdb/v1.9/features/clustering-features/#shard-movement 。
InfluxDB 的 Cluster 版本现在设计如下:https://docs.influxdata.com/enterprise_influxdb/v1.8/concepts/clustering/
replication factor 如果设置为 X,那么一个 N 个 Data Node 的集群会配置 floor(N/X) 个 Shard,然后这里会保证每个几乎机器都会被复制这些东西:
For example we have a shard group for
2016-09-19that has two shards1and2. Shard1is replicated to serversAandBwhile shard2is copied to serversCandD.
(我也不知道为什么这么设计,有人可以告诉我吗?)
这里会根据 hash 挑选写入的 shard,来做热点写打散:
1 | // key is measurement + tagset |
写入的时候,可以配置 write-consistency,不过我感觉基本都是 RWN 都不算的简单同步复制的变种:https://docs.influxdata.com/enterprise_influxdb/v1.8/concepts/clustering/#write-consistency
这里还有个 hinted handoff,和 Dynamo 那套一样,都是故障时写顺延。
Compaction & Deletion
因为热点是写优化的,所以某个 ShardGroup 再不会写之后,相对来说会变成冷的,可以切成一些读优化、省空间的结构。而 Shard Group 本身也会过期,所以是需要删除的。
一些 Schema 相关的讨论
https://docs.influxdata.com/enterprise_influxdb/v1.9/concepts/schema_and_data_layout/
基本上是在教你「怎么用我们的数据库」。
存储引擎: TSM(Time-Structured Merge Tree)
每一个 Shard 都包含着 WAL 和 TSM 文件,这类似 LSM 的 WSL 和 SSTable。TSM 存储引擎包含:
- 内存索引:跨 Shards 共享,提供对
measurements、tags和series的快速访问。这个可能会持久化成下面的 TSI。 - WAL:Shard 的写入优化格式
- Cache:对 TSM 的 WAL 缓存,类似 LevelDB/RocksDB 的 MemTable(我一眼以为是 BlockCache)
- TSM Files: 类似 SSTable,但着重于列式、压缩的格式
- FileStore: TSM Files 的 Manager,控制文件层面的增删访
- Compactor/Compactor Planner: 压缩相关。这里是希望把数据转成更读友好的形式
- Compression: 因为是列式数据,所以需要特定的压缩。有的 Pattern 是固定的压缩方式,有的 Pattern 则是根据数据分布来压缩的。
需要注意的是,对引擎的写入是 Batch 写入的,可能用户的客户端/agent会 Batch 采样数据过来,然后往热的 Shard Group 写数据。
WAL
当写入请求过来的时候,会先往 WAL 里面写入。WAL 以 10MB 为一个 Segment,然后批量压缩写入,格式如下:https://github.com/influxdata/influxdb/blob/master/tsdb/engine/tsm1/wal.go#L705-L722
1 | // The entries values are encode as follows: |
整个 Batch 在组织成如上格式之后,在写入的时候还会被 snappy 压缩:
1 | b, err := entry.Encode(bytes) |
文档上显示,单台机器上,每个 Shard 都会有一个 WAL 流,InfluxDB 致力于将其改成同一个 WAL 流。
Cache
The Cache is an in-memory copy of all data points current stored in the WAL. The points are organized by the key, which is the measurement, tag set, and unique field. Each field is kept as its own time-ordered range. The Cache data is not compressed while in memory.
这里提供同一种类型的快速访问. 看实际代码,Cache 会把实际存储 dispatch 到一个叫 ring 的结构体上。这是一个 Bucket + Concurrency Hash Map,逻辑大概如下:
1 | // ring is a structure that maps series keys to entries. |
注意 store 存储的 map[string]*entry,这里实际上是:
1 | // entry is a set of values and some metadata. |
这个 Values 就是前面 WAL 写的时候那个,是不是一切都连起来了!
TSM 文件
TSM 文件类似 LSM 的 SSTable,包含下面几个区域:
1 | +--------+------------------------------------+-------------+--------------+ |
详细见:https://docs.influxdata.com/influxdb/v1.8/concepts/storage_engine/
需要注意 TSM 和 SSTable 的区别:
- 单个 Block 里面只有同一个 Series Key,里面的类型是相同的,可以用 Column Compression 来处理。除此之外,它还有 Timestamps 区段。
- 不同的 Block 可能拥有相同的 Series Key
- Series Key 按顺序排放
Compaction
- 内存拿到 Snapshot,然后 Compact 到文件上
- Level Compaction: 类似 LevelDB
- Index Optimization: engine 层好像不做这个,文档上写的是 Level4 大量堆积之后,拆分到一个存储/读均优化的结构。
- Full Compaction
需要注意的是,这里很鸡贼,说是 Level Compaction,实际上是 Tiered Compaction. 热文件是多写少读的,可以理解,最后数据冷了应该可以 Full Compaction 或者 Index Optimization,做成读优化的结构。
Write / Update / Delete / Query
这里着重需要理解 Delete。Write 这边会先进 Cache,然后等待 WriteSnapshot 进行。Update 就直接更新,等 Compaction 操作,因为这边会先读上面再读下面。Delete 的流程很诡异,这里会给内存删除,然后给每个有这个 key 的文件写一个 Tombstone 文件。读的时候做 Merge,感觉他这个对更新和删除就不是很友好。
查询这边其实就类似 LevelDB 查询了。不过我好像没太看到一些算子下推的操作,感觉对 AP Workload 支持一般般?
关键路径代码
写入入口, 会把请求分发到 Cache 和 WAL
1 | // WritePoints writes metadata and point data into the engine. |
CompactCache 会完成 WAL -> TSM, 这里调用 WriteSnapshot 做 类似 Major Compaction 的操作:
1 | // compactCache continually checks if the WAL cache should be written to disk. |
而下列会构建 TSM 具体的 Blocks, 也包含了相同类型列的 Compression。
1 | func (c *cacheKeyIterator) encode() |
Compact 关注:
最上层触发在:
1 | func (e *Engine) compact(wg *sync.WaitGroup) |
下面逻辑:
1 | // CompactFull writes multiple smaller TSM files into 1 or more larger files. |
索引: TSI (Time Series Index)
InfluxDB 有一个 Series Cardinality 的概念,其实很好理解。回顾一下,Series Key 组成是:
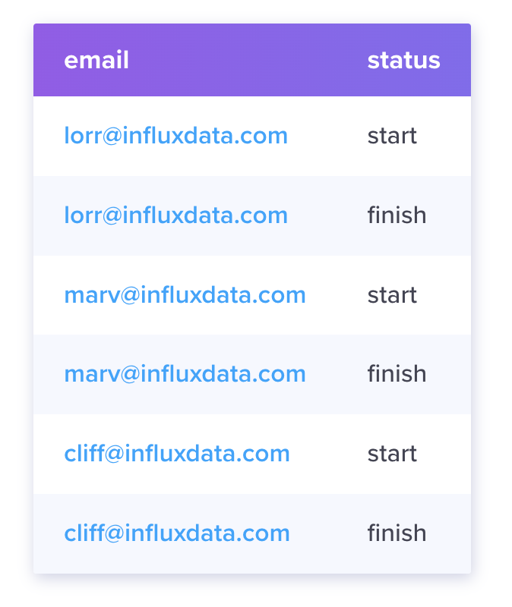
这里我们会发现,对于 email 和 status 这两个 tag,这个 tag 我们虽然支持一堆 string 形式的 key,但是它的选择空间可能不是很大,这里提供了一定的优化空间。同时,如果 Series Key 数量很多,那这个可能会生成过多需要查询的 Index,这给系统带来了很大开销。
还有一种场景,如上,指定 status = start,不指定 email,也总得 AP 吧,这里处理就得扫一堆 TSM 的 Index 了。
这个地方,这里提供了反向索引,它对 <measurement, tag set> 中 measurement 和 Tag 的任意一项到 Series Key 提供了映射。它也是一个有序结构。它的目的如下:
The goal is that the number of series should be unbounded by the amount of memory on the server hardware. Importantly, the number of series that exist in the database will have a negligible impact on database startup time.
可以看到,TSI 大概有这几种类型:
- Index: TSI instance,单个 Shard 会有一个 Index
- Partition: Index 内部会分成多个 Partition,来做 IO 和并发。每个 Partition 会对应不同的存储文件。
- LogFile: TSI 的日志文件
- IndexFile: TSI 最重要的部分之一,表示对应的实际索引
Partition 这个概念很让人困惑。实际上这是个写入优化的措施。写入的时候,利用 Partition 来做并行化,读取的时候,需要从每个 Partition 来 PointGet,或者 Merge Partition 的结果。我个人感觉这东西稍微有点过度设计了…
可以看到,它对外提供了下列接口(实际上是 tsdb/index.go 的 Index 这个 interface,TSM 内存那节有个类似的):
1 | // ForEachMeasurementName iterates over all measurement names in the index, |
和写入:
1 | // CreateSeriesIfNotExists creates a series if it doesn't exist or is deleted. |
对于任何写入,这边会内存有各种 mapping,写 WAL。最后构建成 TSI File,格式参照:https://github.com/influxdata/influxdb/blob/master/tsdb/index/tsi1/doc.go#L65 ,分为:
- Series Block: 存放了所有 Series Key,用 Hash Index 来加速
- Tag Block: 存放了 Tag Key, Tag Value 到 Series Key 的映射,可能有多个 Block
- Measurement Block: 存放 Measurement 的映射
注意,这中间还有 key 的 HashMap,来加速查找。同时,这里有合并多个 TSI 的需求,这里会写入 HLL++,并记录 key 和删除的 key,当合并的时候,可以根据 HLL 计算出大概的结果和空间放大,来调度 Compaction。
参考
https://github.com/influxdata/influxdb/tree/master/tsdb
- TSI: https://github.com/influxdata/influxdb/tree/master/tsdb/index
- TSM:https://github.com/influxdata/influxdb/tree/master/tsdb/engine
- 一些协议:https://github.com/influxdata/influxdb/blob/master/tsdb/internal/fieldsindex.proto
- 官方一些 detail 文档:https://docs.influxdata.com/enterprise_influxdb/v1.9/concepts/time-series-index/
博客:
- 这里有一系列博客,简中大部分 InfluxDB 的二手文档基本都参考了这个: http://hbasefly.com/2017/12/08/influxdb-1/
- Compaction 看代码看的我有点点晕,参考了:https://www.jianshu.com/p/601d97507c0f