x86 basics and code analysis with ai
在看一个 pr 的时候 [1],我尝试把它 port 到 C++ 时候发现有一些地方比较奇怪,如 godbolt https://godbolt.org/z/q8xjb8Ehe,这里 gcc 生成了没有 memcpy 和 memset 的代码,一种迫切的欲望让我想看懂这块代码。但我其实一点都不懂 x86,哈哈…
X86 Basics
x86 这里有不同的 “DataType”:

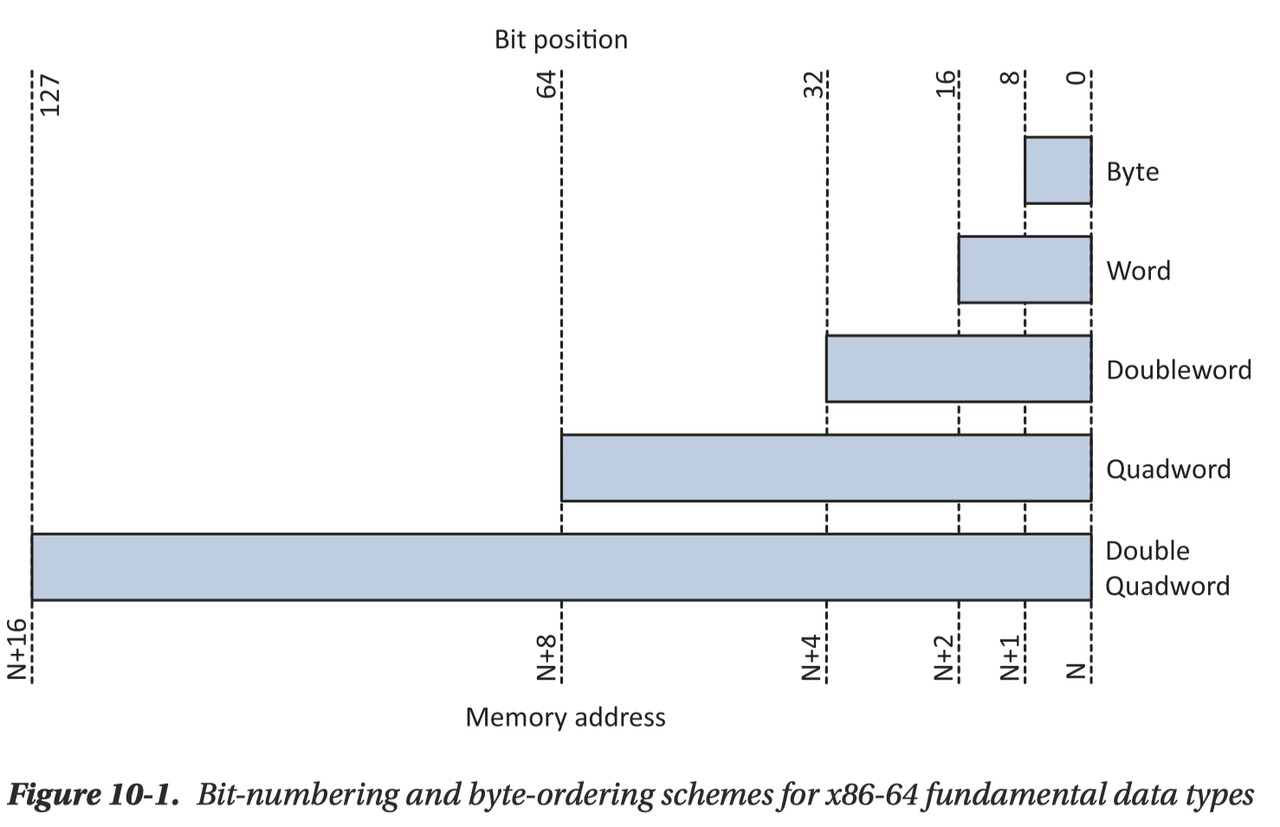
之后会看到,我们很多指令和它们相关。
寄存器
x86-64 大体寄存器如下图。我们可以看到,这里有 General Purpose Register 和 {TODO}
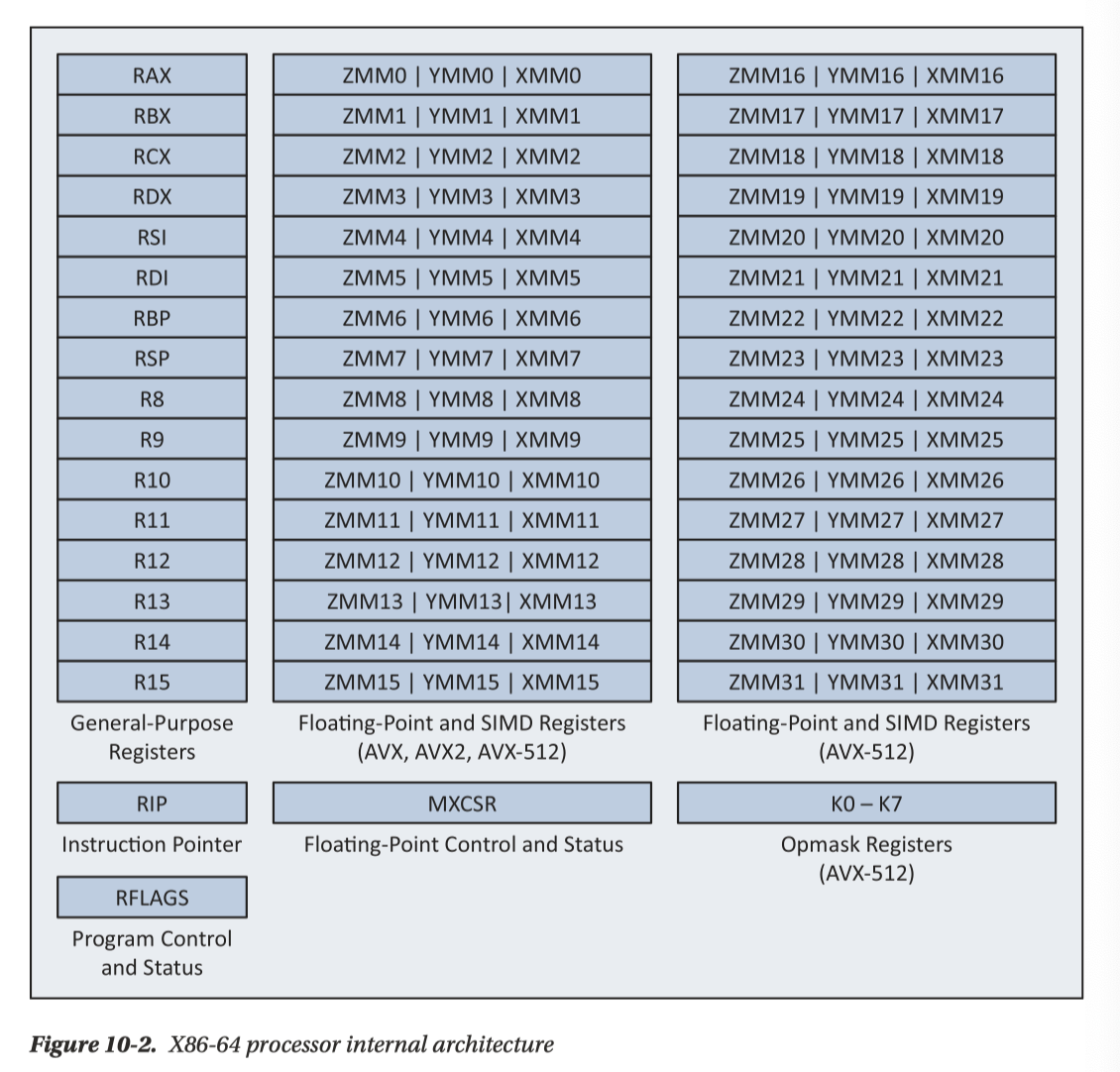
General Purpose Register 如下图:

关于这块,还有个问题比较有意思:CPU寄存器的命名有没有来由? - 知乎 https://www.zhihu.com/question/351139937
此外,还有一些比较有意思的东西:
尽管它们被指定为通用寄存器,但 x86-64 指令集对其使用施加了一些值得注意的限制。多条指令要么需要要么隐式使用特定寄存器作为操作数。这是从 8086 继承而来的传统方案,表面上提高了代码密度。例如,imul(乘以有符号整数)指令的某些变体将计算出的乘积保存在 RDX:RAX、EDX:EAX、DX:AX 或 AX 中。此处使用的冒号表示法表示最终乘积存储在两个寄存器中,第一个寄存器保存最高有效位。 idiv(除以有符号整数)要求将整数被除数加载到 RDX:RAX、EDX:EAX、DX:AX 或 AX 中。 x86-64 字符串指令分别使用寄存器 RSI 和 RDI 作为源缓冲区和目标缓冲区;使用重复(或长度)计数的字符串指令必须将此值加载到寄存器 RCX 中。
这里面,使用上有一些 idiom
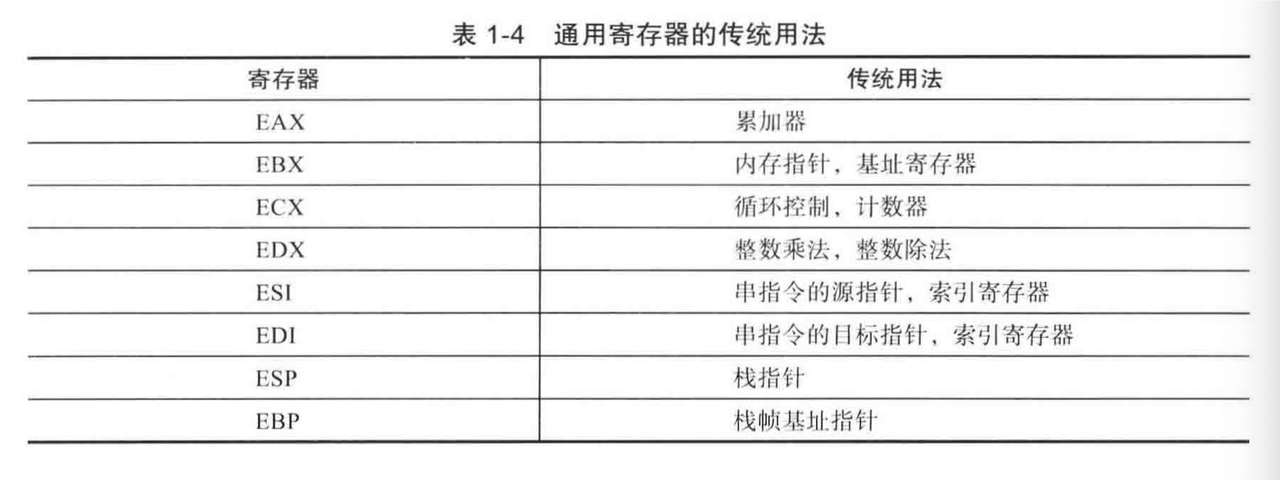
SIMD/Float 有关的寄存器见之前的博客:https://blog.mwish.me/2024/03/24/SIMD-Extensions-and-AVX/
基本指令介绍
在介绍 calling convention 之前,我们可以介绍一下基本的指令
Data Transfer 和寻址模式
我们在很久之前(我刚毕业的时候,哈哈…)介绍过 RISC-V,可以看到 rv 没有这么多狗屁倒灶。这里有个乐子就是 x86 mov 据说是图灵完备的,很神秘。
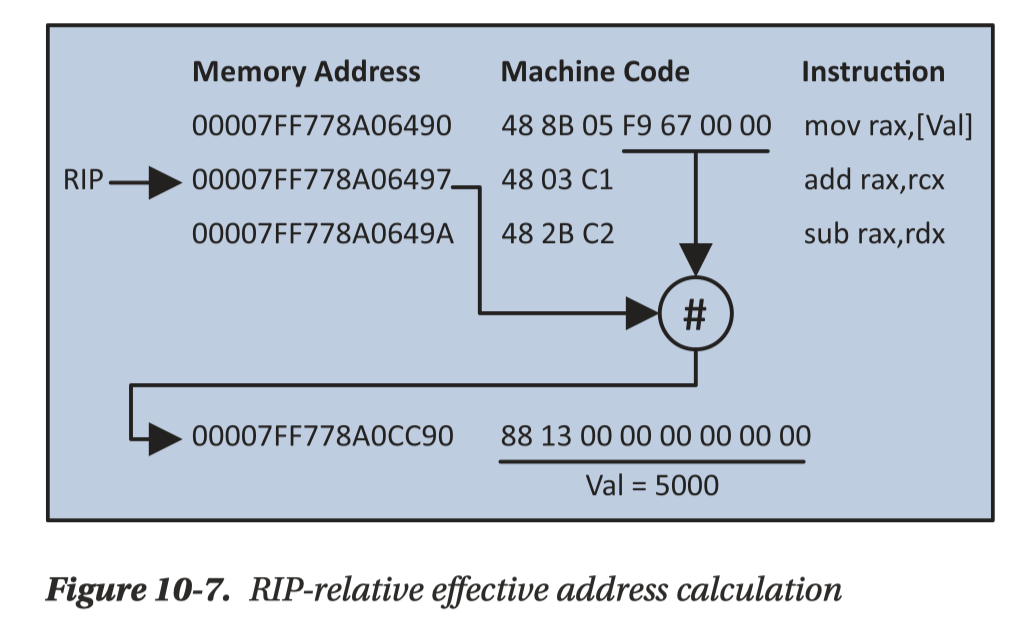
上面的规则看上去无所不能,所以我们直接关注有什么是「不能」的:
- The destination cannot be a constant (duh!)
- You cannot access memory twice in one instruction
有一条比较有意思的常见指令 lea,就是算出寻址后的位置,然后给对应的寄存器
1 | lea rax, [var] |
此外,这里还有一条 push 指令,会把 rsp - 8, 然后把数据拷贝上去;pop 则相反,rsp + 8,然后 pop 出数据
1 | push rax |
基本运算
这里需要记住浮点数那堆指令集。这里不介绍,但是有一些特殊的可以快速记忆一下
1 | and rax, 0fH -- 给低位清零 |
Control Instructions
我们有个最初的 unconditional jump,这个一定很好理解,就不介绍了:jmp。
另一个关键指令是 cmp,cmp 的限制和 mov 一样,这里会设置对应的状态寄存器。之后这里可能可以有对应的 j{condition} 指令,condition 代表跳转的条件。猜一猜下面这几个都是啥:
1 | jne, jz, jg, jge, jl, jle, js |
答案列在下面
| Instruction | Useful to… |
|---|---|
| jmp | Always jump |
| ja | Unsigned > |
| jae | Unsigned >= |
| jb | Unsigned < |
| jbe | Unsigned <= |
| jc | Unsigned overflow, or multiprecision add |
| jecxz | Compare ecx with 0 (Seriously!?) |
| je | Equality |
| jg | Signed > |
| jge | Signed >= |
| jl | Signed < |
| jle | Signed <= |
| jl | Signed < |
| jle | Signed <= |
| jne | Inequality |
| jo | Signed overflow |
此外,还有 call 和 ret. 在 RISC-V 中有差不多的指令。
这里还有个指令是 cmov 族,比如:https://kristerw.github.io/2022/05/24/branchless/ 。这种用于在短指令的时候帮助生成 branchless 友好的代码
Calling Convention
这里有:
- Ykiko 大佬的博客,这段介绍 C++ 的 Calling Convention 的部分非常详细 https://www.ykiko.me/en/articles/692886292/
- https://en.wikipedia.org/wiki/X86_calling_conventions wiki
- https://aaronbloomfield.github.io/pdr/book/x86-64bit-ccc-chapter.pdf
1-3 看完可以回头看看 1。这里阅读之前,可以看到 x86 非 64 位有一堆神鬼莫测的坑,包括不同的 calling convention。64 位基本统一到了 System V ABI 和 Windows ABI。前者在 Linux MacOS 等系统上为事实标准。著名的神坑 Red Zone 也是这个标准下的一部分。
这个标准的 Spec 见: https://gitlab.com/x86-psABIs/x86-64-ABI
首先关注下面
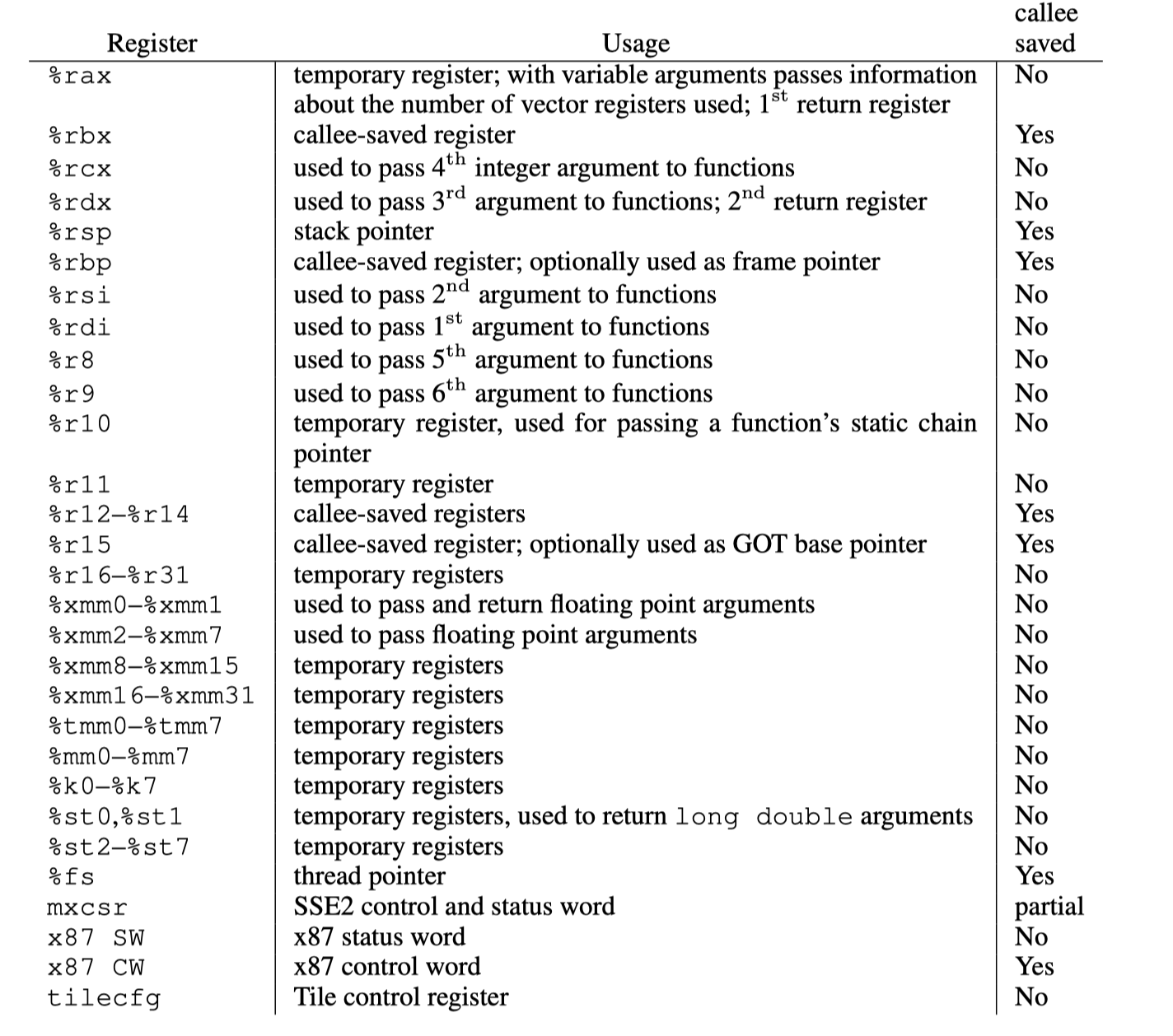
关于参数传递,这里有意思的是 16B 以下的 pod 结构可能会拆成两个寄存器(见 spec 里面的 Parameter Passing 一节,这里也有个帮助理解的 SO https://stackoverflow.com/questions/65992291/x86-64-system-v-abi-argument-classification-for-parameter-passing )
简单规则是(这里我大概读了一下原文,意外的很简单):
- 参数类型有:MEMORY, SSE, SSEUP, INTEGER, X87_FPU 和一些为初始化的条件
- MEMORY 在内存栈上传递参数,Integer 在
%rdi, %rsi, %rdx, %rcx, %r8, %r9这几个寄存器中参数传递,SSE/SSEUP 用%xmm0 - %xmm7 - 64B 以下的对齐结构中(不对齐只走mem),有的结构能拆到寄存器中传参数,不考虑 SSE 类型的话,这里需要不大于 16B,然后允许拆分成寄存器
返回规则也是用这一套做类型判定的:
MEMORY 类型: 调用者在内存中预留空间,并将该空间的地址作为第一个参数传递给函数。函数将返回值存储在这个空间中,并返回该地址(在 %rax 中)。这里可以看到有点像咱们写代码里面直接输出参数了。
INTEGER 类型: 返回值存储在下一个可用的通用寄存器 %rax 或 %rdx 中。
SSE 类型: 返回值存储在下一个可用的 SSE 寄存器 %xmm0 或 %xmm1 中。
SSEUP 类型: 返回值存储在上一个使用的 SSE 寄存器的下一个可用 8 字节块中。
Stack Frame and Red Zone
The 128-byte area beyond the location pointed to by %rsp is considered to be reserved and shall not be modified by signal or interrupt handlers. Therefore, functions may use this area for temporary data that is not needed across function calls. In particular, leaf functions may use this area for their entire stack frame, rather than adjusting the stack pointer in the prologue and epilogue. This area is known as the red zone.
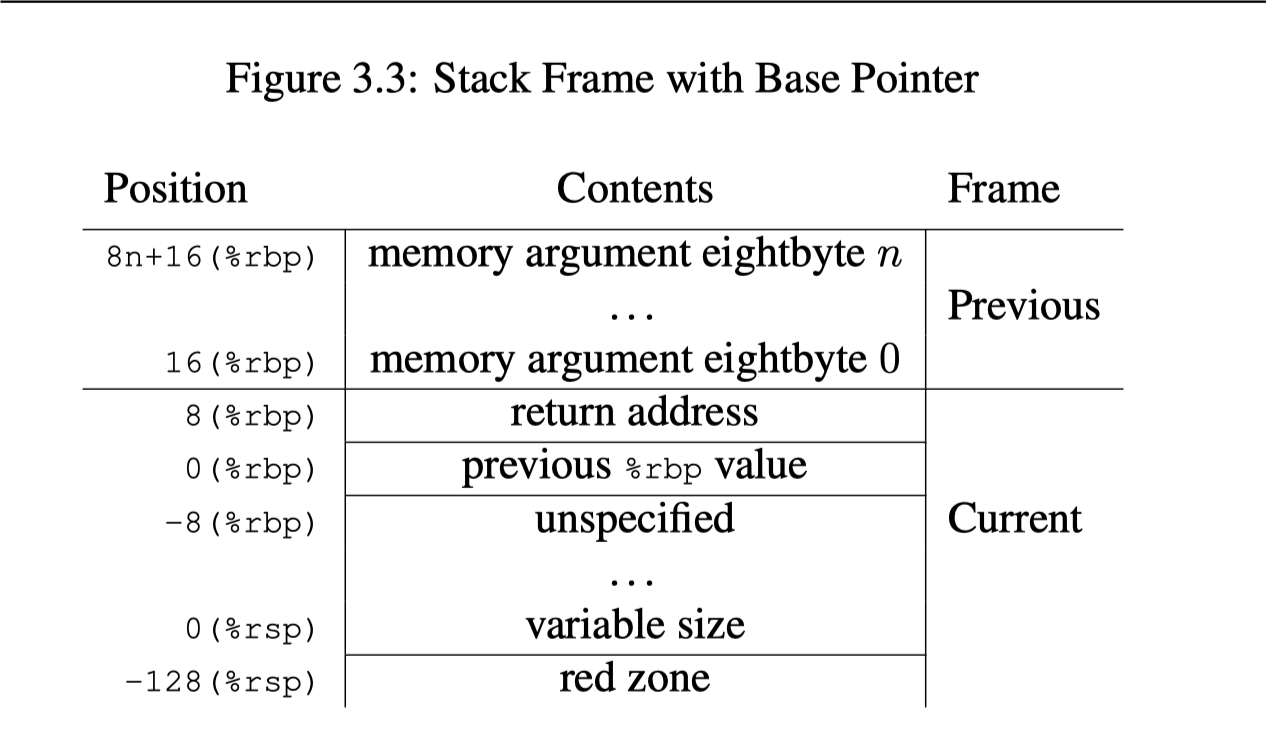
流水线
这里可以看到下面的 CPU 执行。这里也可以看到,指令的执行是个很含糊的概念,和很多东西有关,但是代码多也不一定真的就慢了,具体还是得靠 benchmark 工具来测试。
Ask AI to rewrite code into C++
回到我们最初的问题,我们现在已经熟悉了 x86 的指令,但你以为我就会看他代码了?我先把全部代码贴一下
1 | makeInline1(char const*, int): |
然后这里,我让 gemini 帮我把这段代码改写成 C 语言
1 | c_type makeInline1(const char* data, int32_t size) { |
我们不难看出,这段代码是错的。或许有一天 AI 或者 fine-tune 的 ai 能生成对应的代码,但是至少…今天不行?
那么我们想到…C汇编转 goto 会不会好一些?还真是。我把 prompt 改成
能再次尝试把汇编翻译为 C 语言代码吗?跳转的地方,比如
和
2
jne .L17使用 Goto 来翻译
1 | c_type makeInline1(const char* data, int32_t size) { |
成了兄弟!完美!
乌龙
最后发现这段代码其实就是 memset,memcpy 的具体实现这个例子本质上是 gcc 把 memcpy memset 拆开了,拆到了计算里面. 为什么 LLVM 没有这个呢,我也不知道,可能等后续探索了。
References
- https://github.com/apache/arrow-rs/issues/6034 Improve performance of constructing
ByteViews for small strings - https://godbolt.org/z/q8xjb8Ehe 上面这对应的可优化代码
- https://gitlab.com/x86-psABIs/x86-64-ABI x86-64 System V ABI
- Ykiko 大佬的博客,这段介绍 C++ 的 Calling Convention 的部分非常详细 https://www.ykiko.me/en/articles/692886292/
- https://en.wikipedia.org/wiki/X86_calling_conventions wiki
- https://aaronbloomfield.github.io/pdr/book/x86-64bit-ccc-chapter.pdf
- https://kristerw.github.io/2022/05/24/branchless/