/** * The switch case statements follow * BITSET_CONTAINER_TYPE -- ARRAY_CONTAINER_TYPE -- RUN_CONTAINER_TYPE * so it makes more sense to number them 1, 2, 3 (in the vague hope that the * compiler might exploit this ordering). */
/** * Macros for pairing container type codes, suitable for switch statements. * Use PAIR_CONTAINER_TYPES() for the switch, CONTAINER_PAIR() for the cases: * * switch (PAIR_CONTAINER_TYPES(type1, type2)) { * case CONTAINER_PAIR(BITSET,ARRAY): * ... * } */ #define PAIR_CONTAINER_TYPES(type1, type2) (4 * (type1) + (type2))
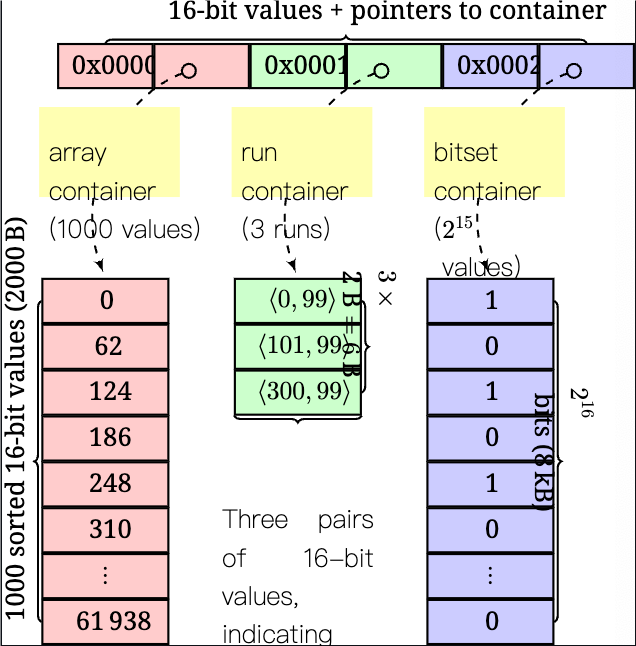
/* struct array_container - sparse representation of a bitmap * * @cardinality: number of indices in `array` (and the bitmap) * @capacity: allocated size of `array` * @array: sorted list of integers */ STRUCT_CONTAINER(array_container_s) { int32_t cardinality; int32_t capacity; uint16_t *array; };
/* struct rle16_s - run length pair * * @value: start position of the run * @length: length of the run is `length + 1` * * An RLE pair {v, l} would represent the integers between the interval * [v, v+l+1], e.g. {3, 2} = [3, 4, 5]. */ structrle16_s { uint16_t value; uint16_t length; };
typedefstructrle16_srle16_t;
/* struct run_container_s - run container bitmap * * @n_runs: number of rle_t pairs in `runs`. * @capacity: capacity in rle_t pairs `runs` can hold. * @runs: pairs of rle_t. */ STRUCT_CONTAINER(run_container_s) { int32_t n_runs; int32_t capacity; rle16_t *runs; };
/** * A shared container is a wrapper around a container * with reference counting. */ STRUCT_CONTAINER(shared_container_s) { container_t *container; uint8_t typecode; croaring_refcount_t counter; // to be managed atomically };
/** * Add value to the set if final cardinality doesn't exceed max_cardinality. * Return code: * 1 -- value was added * 0 -- value was already present * -1 -- value was not added because cardinality would exceed max_cardinality */ staticinlineintarray_container_try_add(array_container_t *arr, uint16_t value, int32_t max_cardinality){ constint32_t cardinality = arr->cardinality;
// best case, we can append. if ((array_container_empty(arr) || arr->array[cardinality - 1] < value) && cardinality < max_cardinality) { array_container_append(arr, value); return1; }
constint32_t loc = binarySearch(arr->array, cardinality, value);
/** * Roaring-internal type used to iterate within a roaring container. */ typedefstructroaring_container_iterator_s { // For bitset and array containers this is the index of the bit / entry. // For run containers this points at the run. int32_t index; } roaring_container_iterator_t;
/** * A struct used to keep iterator state. Users should only access * `current_value` and `has_value`, the rest of the type should be treated as * opaque. */ typedefstructroaring_uint32_iterator_s { constroaring_bitmap_t *parent; // Owner const ROARING_CONTAINER_T *container; // Current container uint8_t typecode; // Typecode of current container int32_t container_index; // Current container index uint32_t highbits; // High 16 bits of the current value roaring_container_iterator_t container_it;